For a long time, I didn’t use voice search. I wanted Siri to search my apps and photos, but it didn’t, and still doesn’t really. For most people, Siri is that thing that gets in the way of seeing the clock when you accidentally hold the home button.
But I didn’t feel right about how quickly we had dismissed voice search. Until Apple gives Siri deeper reach into apps, we are left with an often ineffective experience. I think the best voice assistant right now is Alexa on the Amazon Echo, since she can order you an Uber, a pizza, and play music from your Spotify. The problem is it’s hard to view family photos or watch Netflix on a black tennis ball can.
{kind=link}
So I created a voice-search power tool. It searches across the web and deep into your online accounts like Dropbox, Gmail, Evernote, Twitter, and Facebook without requiring permissions or seeing your data. And it can learn to search almost any website with very little effort.
When Apple first announced Siri, I thought that it wouldn’t be long until I could use it to search within apps. You might say “Show me Barack Obama’s Twitter” and get taken into the Twitter app to see the former president’s profile.
Years later, Siri hasn’t learned to search within apps, and neither has Google. On a phone or a computer, it isn’t possible to search your accounts with your voice. Digital assistants break down when I’m trying to find something that isn’t on Wikipedia, like a photo of my wife and I on vacation.
This motivated me to build an improved voice search for my new tab page. I spend a lot of time on Twitter, Dropbox, and Google Photos, so they were a natural place for me to start. I used Web Speech API for voice recognition and simplistic language processing. The result looks like this:
I can open a new tab and jump straight to content without working to get there. It takes less mental effort to ask for what you want than it does to go to a site and find it yourself.
Deep voice search
Google Photos and JustWatch.com best demonstrate the value of deep-reaching search results from a new tab page.
Google Photos has excellent natural language search, letting you search for people, places, things, times, and more. Deep-searching Google Photos dives straight into the content, getting to these super specific search results directly using simple language commands.
Here’s another example: I don’t have a cable subscription. I use a combination of streaming services to watch movies and TV shows, but it’s hard to know where to find the movie I want to watch. JustWatch.com helps me search across multiple streaming services to see what is available where.
The problem with using the JustWatch website is that it requires a lot of steps:
- Answer what country you are in. Whole page reloads.
- Locate the search bar, type and hit enter. Another page load.
- Find and click the service you want. That loads the movie or episode page.
- Play the video.
With a deep voice search, the process is much simpler (and a bit quicker). Say what you want to watch, pick your service, and play. Here they are side by side for comparison:
Saving two or three seconds may not seem like a lot, but when it comes to page load times, every second counts. And when I’m thinking about Free Willy, I have to change gears mentally to pick my country, then change back to thinking about Free Willy. The cognitive load is much lower using voice search, I just say what I want to watch. That plus the time savings makes for a much better experience. It’s so much more frictionless that I hesitate to use JustWatch unless I can search with my voice.
How it works
The script tries to find two pieces out of the spoken phrase: a “query string” which tells me what to search, and a “keyword” which tells me where to search. I use a few other types of phrases for context. Below is an example sentence broken into components:
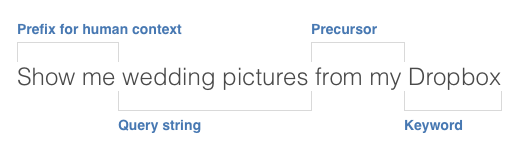
I baked in some keywords for nearly a hundred popular sites like Facebook, Twitter, YouTube, Wikipedia, Amazon, Google services like Gmail, Drive, Maps, Keep, and Photos, Dropbox, Spotify, Evernote, Netflix, Hulu, HBO Go, Pinterest, Airbnb, and lots more. Give one or all of them a try, you’ll be surprised to see how useful it is.
Design considerations
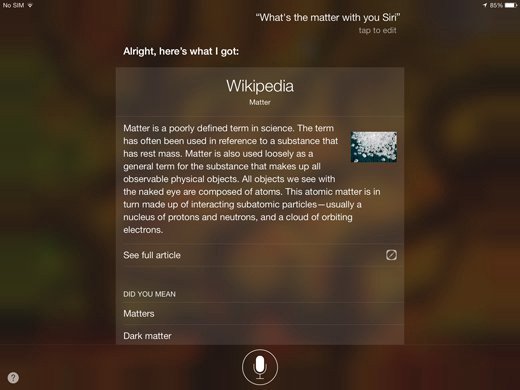
Instead of having an AI personality like Siri, I decided to make my voice search a modified web search. I know how a web search works, it’s familiar and predictable. It will always give me some kind of result. Using a web search as the default for voice instead of using a personality prevents confusing non-result screens like the one below:

On top of predictability, search is also more useful and practical. Digital personalities often are more distracting than delightful, getting in the way more often than helping. They ask you to have a conversation, then present you with information that may or may not be relevant:
First impressions make a big difference. People using something new are often unsure or even afraid to do something wrong and “mess something up.” When you use something for the first time and it sends you somewhere unintended, it’s unlikely you will give it a second or third chance.
Both Siri and Google have a fundamental problem in this area. Most voice searches automatically detect when you are done talking, which presents three problems:
- Stage fright. New users can be unceremoniously cut off as they try to think of what to say. This puts pressure on the user, and it can even trigger a stage-fright response.
- Tech is confused by background noise. Noisy environments can also prevent recognition from ever finishing, making voice search useless, even if the words were heard and transcribed correctly.
- Voice recognition is often wrong. It is frustrating to be misheard, and many voice assistants don’t make it easy to cancel when you see that the computer didn’t hear you correctly.
I considered these flaws carefully when crafting the interaction for voice commands. “Press to talk” gives users control, letting them decide when they are done. First-time users aren’t punished for not knowing what they want to say, and if they say nothing, it’s still listening. When you’re done talking, you release the button, preventing background noise from dragging out recognition.
My early prototype immediately redirected you to a page when you released the microphone button. This happened at a startling speed. Speech recognition also isn’t perfect, and with a system that’s instantly thrusting you into the web, it feels terrifying to watch the computer mishear you with no way to correct it. For this reason I added a cancel button with a two second timer.
If the voice recognition is correct, you are taken to the result with ample time to review the text. If it is incorrect, simply click the button to cancel and try again.
Takeaways
Voice-driven interfaces still have limited use. I can’t imagine using my voice for the whole work day. However, when used as a power-tool, voice can help cut through layers of complexity faster than typing. According to the National Center for Voice and Speech, the average rate for English speakers in the US is about 150 words per minute, while average typing speed is only 40 words per minute. Your mileage may vary, test your speaking speed and typing speed to see for yourself.
Finding an Airbnb in a given city or diving straight into a search of your Dropbox account from a single voice search page is impressive, and this type of search will only get better as more sites support natural language search like Google Photos does.
If you want to know how it works or if you want to make something like it, I made a GitHub repo with a detailed ReadMe explaining how it works. Feel free to reach out to me with any questions or comments.
